Some notes of Psychoacoustic Adaptive Filter Topologies
About 15 years ago, I made a simple eq in matlab when I was studying on DSP. Compared with some famed commercial products, I was surprised that their sounds are much, much better than mine. After more study and research, I believe there’s no magic in their algorithms, it’s just because of the filter structures.
Though mathematically identical, a EQ, or we say “IIR filters” have different structures, and the most common four are:
* Direct-Form I ( DF I )
* Direct-Form II ( DF II )
* Transformed Direct-Form I ( TDF I )
* Transformed Direct-Form II ( TDF II )
more details can be found here.
Besides the four basic structures above, there’s also “state-variable filter” and its variants that are really good for audio processing.
more details here.
And even more, if we consider CPU optimization for SIMD instruction sets such as SSE, AVX and NEON, there’s also some forms specialized for parallel processing. There’s no common rule, every implementation may varies from each other.
Okay, now you may have a question: as they are all mathematically equivalent, they shoud have same sound. why we need so many different filter forms? Because they actually have very different sound! each one of them have unique sound.
Though many people are unaware, the sound from each structure are slightly varied. If you choose an improper structure, the sound from your EQ could not possibly be good.
In real world, due to computer quantization error, all filters have some round-noise. if you see the round-noise spectrum of these forms’ output, the difference is significant:
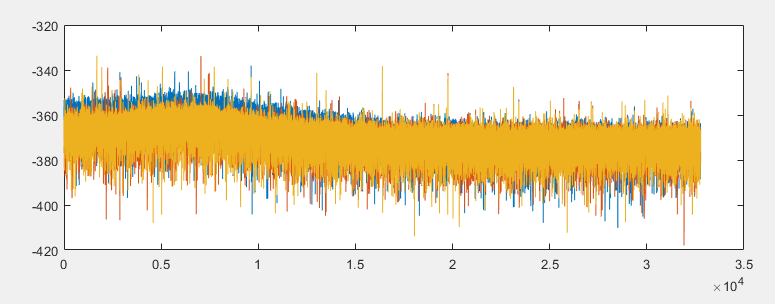
It is obvious that the blue one has much higher noise level at lower frequencies than red and yellow one.
Some audio clips ( DF1, DF2 and TDF1) here:
You may think that the difference is slight. But you won’t use only one EQ band, it’s more often to use many EQ bands on each track, thus the difference is accumulated. It’s not just more noises, bad structures will destroy clarity and smear transients of your mix. So the safest way is to use the structure that have best sound quality.
When developing Kirchhoff-EQ, I devoted to find filter structure that has best sound quality. This is not easy, as there’s not too many articles. After many blind tests, I found it reluctant that there’s no best filter structure, as some behaves well on high frequency, and some on lower.
When I get this conclusion, my first thought was: “Damn, what should I do now?”
I don’t want to have Kirchhoff-EQ specialized on some style, I want it to have good sounding on both low- and high-frequencies, and this means I cannot use one specific filter structure. Luckily, after massive mathematical derivation works (thanks my friend Miles), I designed series of smooth-varying filter structures that change themselves according to filter coefficients. This allows to have optimized sound quality at all frequencies.
So that’s what we called “Psychoacoustic Adaptive Filter Topologies”.