大概15年前,我在学习DSP知识时制作了一个简单的EQ,在和当时的一些高品质的商业产品进行对比后,我惊讶于它们比我的EQ的音质好那么多!在大量的研究之后,我确信,他们的算法没有魔法,只是因为结构!
尽管在数学上完全等价,但IIR滤波器拥有多种不同滤波器结构。最常见的有4种,分别是
– Direct-Form I
– Direct-Form II
– Transformed Direct-Form I
– Transformed Direct-Form II
了解更多请点击:https://en.wikipedia.org/wiki/Digital_filter
对于专业音频来说,除了这四种最常见的,还包括State Variable Filter(这对音频很好)。和它的⼀些变体。
了解更多请点击:https://www.musicdsp.org/en/latest/Filters/92-state-variable-filter-double-sampled-stable.html
更重要的是,如果我们考虑针对 SSE、AVX 和 NEON 等 SIMD 指令集的 CPU 优化,还有一些专门用于并行处理的形式。这里没有通用的形式可供参考,每种实现方法可能会彼此不同。
好的,现在你可能有一个问题:既然它们在数学上都是等价的,所以它们应该有相同的声音。那么,为什么我们需要这么多不同的过滤器形式?因为它们实际上有着非常不同的声音!它们中的每一个都有独特的声音。
虽然很多人不知道,但其实每个结构发出的声音都略有不同。如果您选择了不正确的结构,那么EQ 发出的声音可能不会很好。
在现实世界中,由于计算机量化误差,所有滤波器都有一些舍入噪声。如果你看到这些形式输出的噪声频谱,差异是明显的:
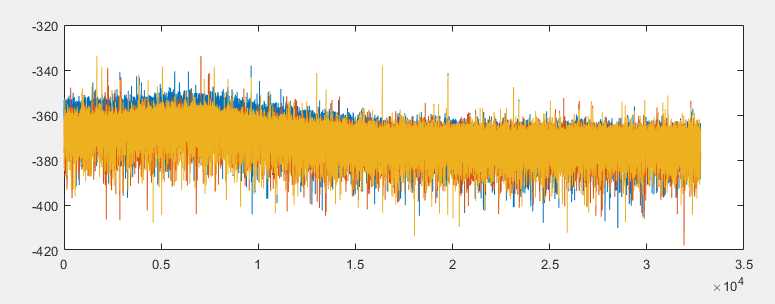
您可以看到蓝色,红色,黄色都是不同的结构的量化噪音,其中蓝色在低频部分明显比红色和黄色要大。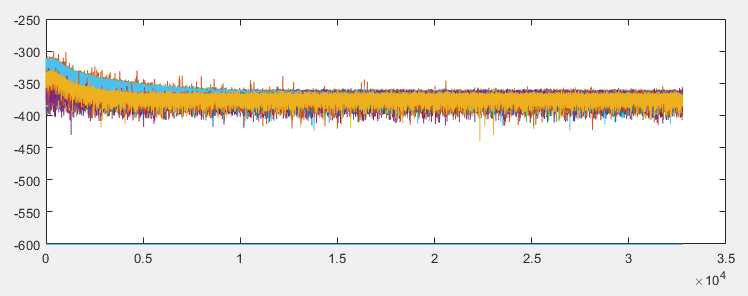
同时,以下是DF1,DF2和TDF1三种的⾳频测试:
或许您会觉得它们的差别微乎其微。但您不会只用一个EQ频段,更经常的是在每个轨道上使用多个EQ频段,从而累积差异。这不仅仅会带来更多的噪音,同时糟糕的结构会破坏混音的清晰度并模糊瞬态。所以最安全的方法是总是使用音质最好的结构。
在我研发Kirchhoff-EQ时,我就致力于寻找音质最好的音质滤波器结构,这并不容易,因为并没有太多可借鉴的文献资料。在经过大量的盲测,我发现没有最好的滤波器结构,因为有些在高频上表现良好,有些在低频上表现良好。我的第一个反应就是: “神啊, 我现在该怎么办”。我不想让Kirchhoff-EQ专门针对某种风格,我希望它在低频和高频上都有很好的声音,这意味着我不能使用一种特定的滤波器结构。幸运的是,经过大量的数学推导工作(感谢我的朋友 Miles),我设计了一系列平滑变化的滤波器结构,它们根据滤波器系数改变自己。这允许在所有频率下优化声音质量。这就是Psychoacoustic Adaptive Filter Topologies PAFT:心理声学自适应滤波器拓扑结构。
发表回复